Problem
Standard policies often overfit to a single training regime and lose performance sharply after distribution shifts or repeated task changes.
Research Project
A reinforcement learning system designed to stay useful after the environment changes, not just while it stays familiar.
This work focused on combining dual-agent PPO training with neuromodulation-inspired adaptation so the policy could recover quickly after distribution shifts while resisting catastrophic forgetting over repeated task transitions.
Paper Preview
This preview links directly to the paper covering the training setup, adaptation strategy, and measured recovery results.
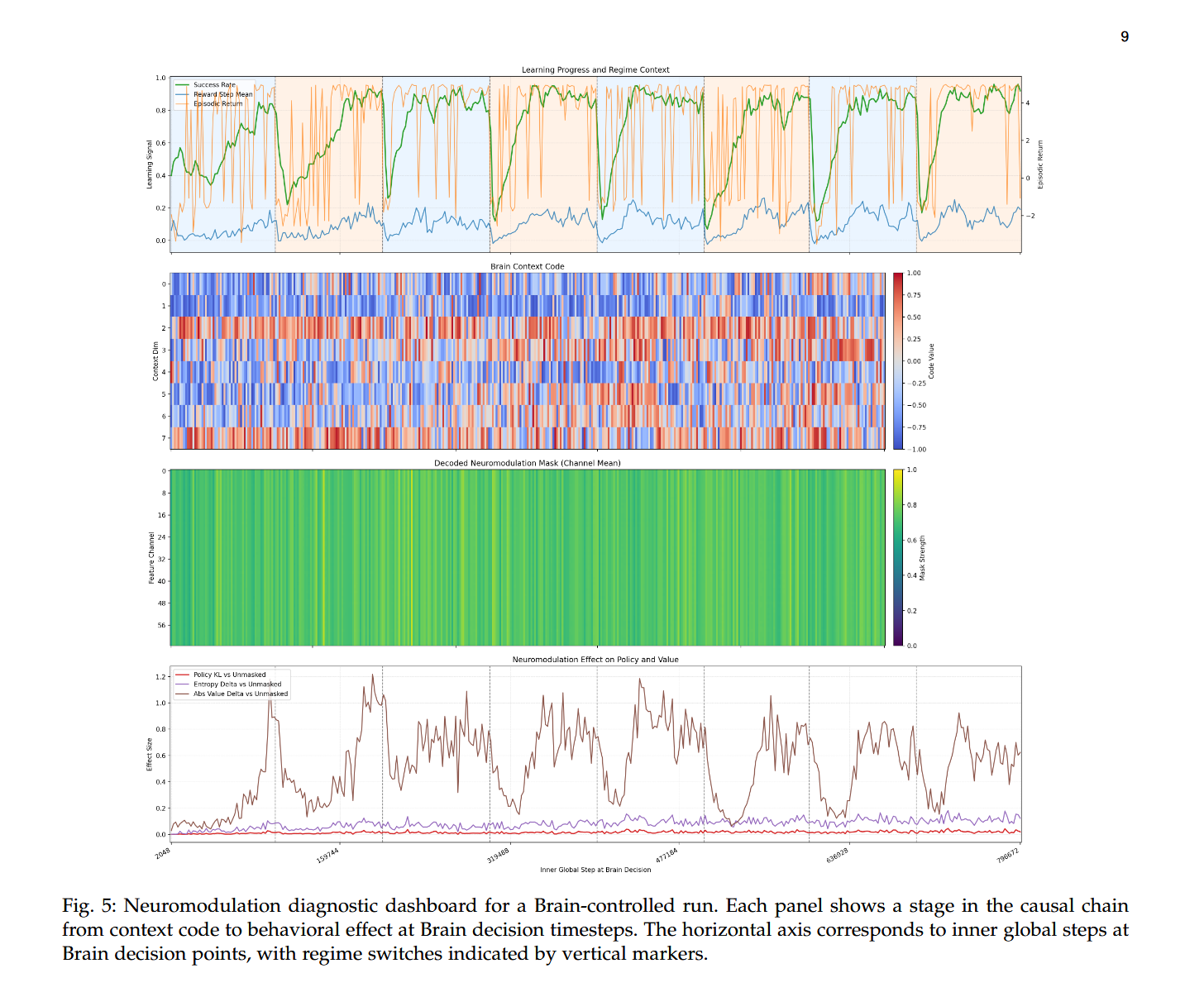
Why This Matters
Non-stationary settings are where a lot of promising RL work falls apart. The goal here was to make policy adaptation a first-class behavior rather than an afterthought, so the agent could recover under changing conditions without resetting to square one.
Standard policies often overfit to a single training regime and lose performance sharply after distribution shifts or repeated task changes.
I structured the system around coordinated PPO agents with adaptation signals inspired by neuromodulation, allowing the policy to respond more fluidly to changing environments.
Preserve useful prior behavior while recovering quickly enough to stay competitive after each environmental shift.
System Design
The system centered on three design choices that made the adaptation loop more resilient under repeated distribution shifts.
Separate policy responsibilities created a cleaner boundary between stable control behavior and fast adaptation behavior.
Modulatory signals were used to help the policy respond to changing conditions without fully overwriting previously learned behavior.
Evaluation emphasized whether the system could recover across repeated shifts, not just succeed once in a favorable setting.
Research Link
Technical Paper
The full paper captures the training setup, evaluation methodology, and adaptation results behind the case study.